近日,研究院林树海团队近日在《自然·通讯》(Nature Communications)、《中国化学快报》(Chinese Chemical Letters)和《分析化学》(Analytical Chemistry)发表三篇研究论文。
在《自然·通讯》(Nature Communications)发表题为LipidIN: a comprehensive repository for flash platform-independent annotation and reverse lipidomics的最新AI脂质组研究成果,推出首个快速、平台无依赖的反向脂质组学质谱AI模型LipidIN,显著提升脂质组鉴定速度与深度。
近年来,液质联用技术(LC-MS)已成为定量脂质组研究的主要方法,但在注释准确率、搜库效率及深度结构解析等方面仍存在显著瓶颈。
该研究首次将保留时间群智能(lipid categories intelligence,LCI)模型与反向脂质组学(Wide-spectrum Modeling Yield network,WMYn)模型引入脂质质谱数据分析,开发出全新的分析软件LipidIN。
传统脂质注释方法在提升准确率、覆盖率、搜库速度及结构解析深度方面存在显著局限,为此我们开发了新型通用型脂质组学分析框架LipidIN。该平台通过构建涵盖分子链组成与碳碳双键位置信息的1.685亿条脂质碎片的分层谱库,并采用优化索引算法实现每秒超1000亿次查询。基于保留时间规律开发的脂质群模型(LCI)将错误发现率控制在5.7%,成功注释跨物种的8923种脂质,同时整合谱图再生成网络(WMYn)通过深度学习重构脂质碎片特征图谱,使目标分子召回率提升20%。在临床队列研究中,LipidIN已成功应用于脂质注释与生物标志物发现,其标准化分析流程显著提升了跨平台数据的可比性与可重复性。
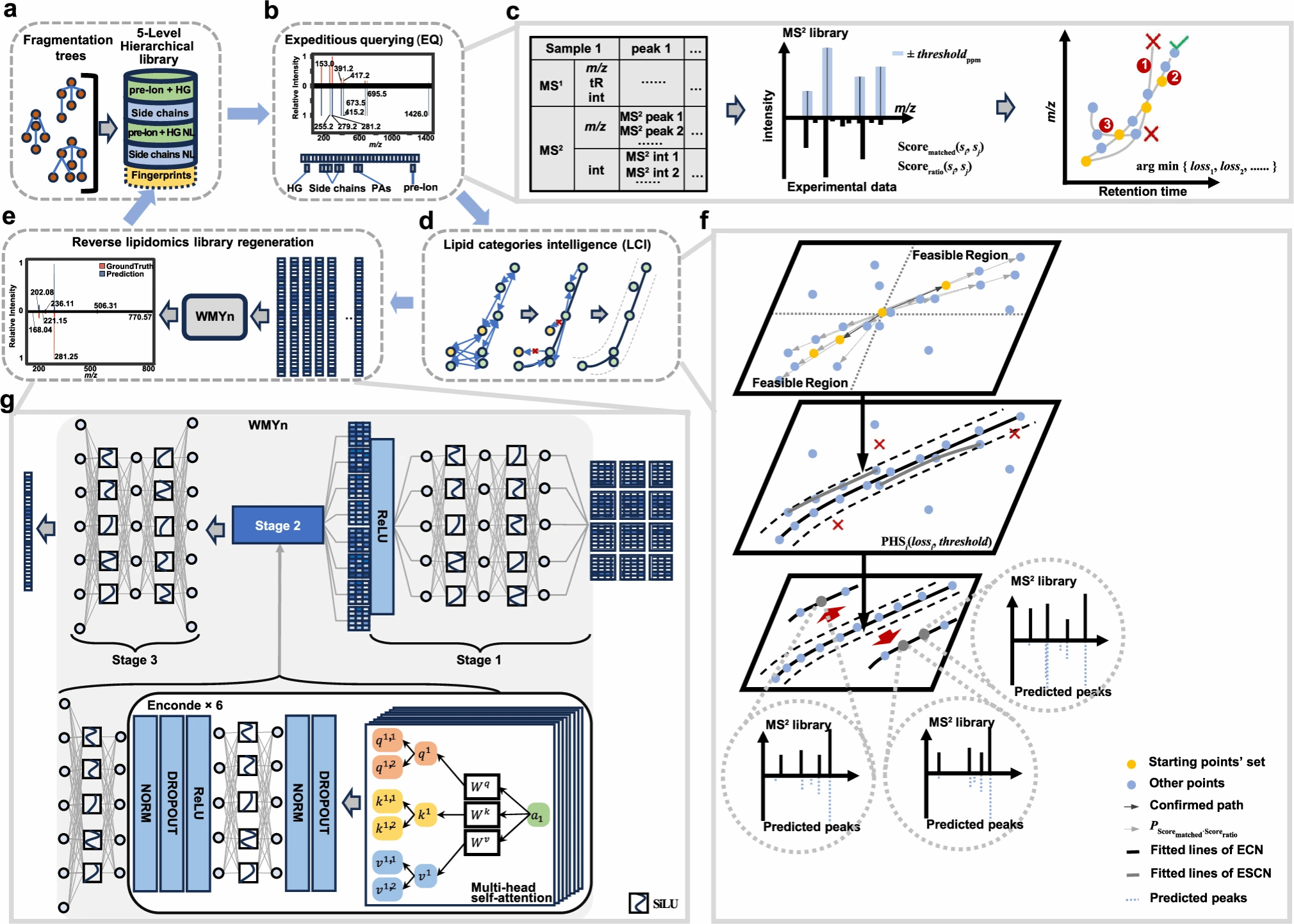
图1. LipidIN计算框架。
在研究结果部分,本文对LipidIN的性能进行了全面评估,并将其与现有的分析工具MS-DIAL,LipidSearch,Spectral Entropy,LipidMatch进行了比较。该基准实验使用了NIST 1950标准品和多篇高影响力的文章数据集。
以下是具体分析的几个要点:
1. 注释速度
为验证目标任务体量对匹配速度的影响,研究团队在低内存个人计算机(单线程CPU环境)上使用公开数据集(MetabolomicsWorkbench ST001794)进行测试,对比EQ算法与Flash Entropy在不同规模MassBank理论谱库中的性能表现。
结果显示,当谱库规模达到千万级时,EQ算法保持稳定匹配速度(完成1000万次搜库仅需2.3微秒),而Flash Entropy在百万级搜库时单次MS2匹配耗时增至0.14秒,速度下降显著。得益于哈希表与二分法的联合优化,EQ算法可在0.23毫秒内完成十亿次MS2谱图比对(每秒可完成超过4万亿次谱图比对),在使用百万级谱库时较Flash Entropy提速约6万倍。
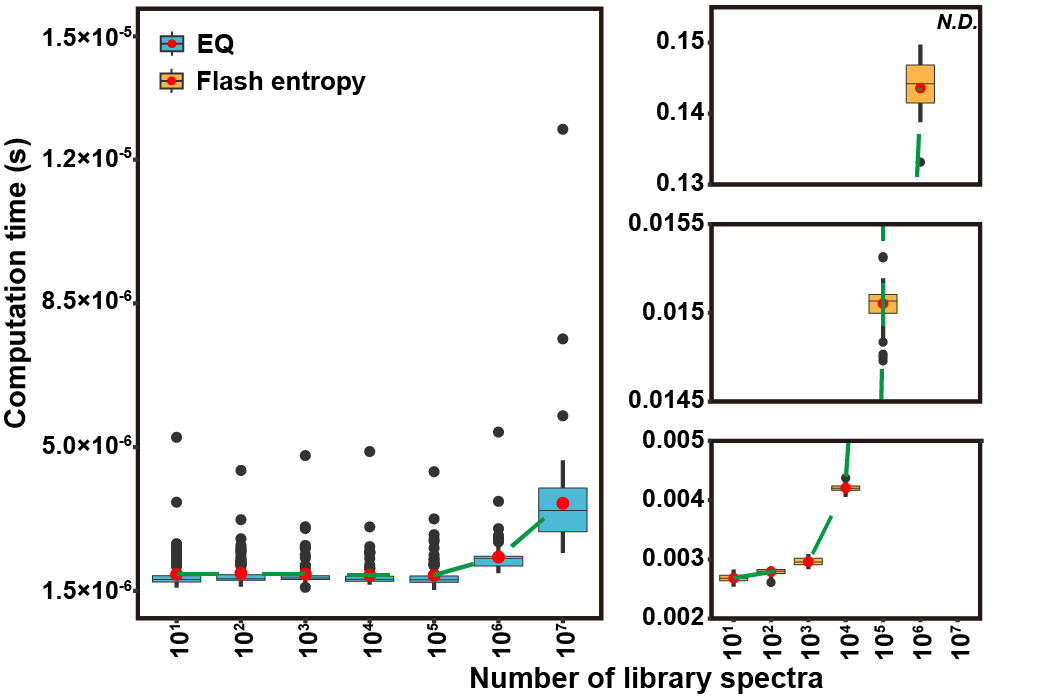
图2. LipidIN的质谱图库查询速度远超Flash Entropy。
2. 注释覆盖度
为验证算法性能,研究团队采用已公开数据集(MetabolomicsWorkbench ST001794、ST002384)对比了MS-DIAL、LipidSearch、Spectral Entropy、LipidMatch等常用小分子化合物注释工具。
实验显示,EQ模块结合MS-DIAL公共数据库在Top-20候选列表中实现约70%召回率(召回率定义为工具与文献注释交集数/文献总注释数),而联合LCI模块的四级分层谱库策略,将召回率提升至90%以上。
3. 假阳性去除率
为验证基于保留时间规则的LCI模块在假阳性注释去除中的有效性,研究团队将其与跨平台脂质注释工具Lipid Data Analyzer (LDA; http://genome.tugraz.at/lda2) 的保留时间预测算法进行对比。
实验结果显示,在绝大多数脂质亚类中,LipidIN的LCI模块在注释准确率上均显著优于LDA方法。这一优势源于LCI模块通过ECN/IUP/ESCN三重保留时间规则建立的动态校正模型,相较于LDA的单维度保留时间过滤策略,能够更精准地识别复杂样本中的错误注释。
4. 高分辨谱图再生
针对WMYn模型的高分辨质谱重构能力,研究团队系统性对比了均值法、线性拟合、多项式拟合及指数拟合等多种谱图预测方法,并基于熵相似度评估预测谱图与标准谱图的一致性。
在Orbitrap Exploris 240质谱系统的333例临床队列样本测试中,较低分辨率(保留两位小数)条件下,所有方法均表现出较高相似性,而WMYn仍以最优得分领先;当保持较高高分辨率(四位小数)时,WMYn的预测精度显著优于其他方法。
进一步将五级谱库整合至Entropy Search框架后,基于MS-DIAL公共数据库的注释实验显示,在0.75相似度阈值下,五级谱库使多数脂质亚类的Top-20召回率显著提升。尽管LipidIN具备独立注释能力,但五级谱库的引入进一步拓展了反向脂质组学的应用边界,验证了其在复杂脂质解析中的独特价值。
该软件针对学术用户开源,其良好的可扩展性使其成为一个极具潜力的工具。更多信息可以访问:https://github.com/LinShuhaiLAB/LipidIN, https://doi.org/10.5281/zenodo.14824498.
厦门大学健康医疗大数据国家研究院为第二单位,硕士生徐昊、姜天航和福建医科大学附属协和医院林雨翔及厦门大学张蕾博士为共同第一作者,厦门大学林树海教授、宁波东方理工大学(暂名)蔡宗苇教授和集美大学曾珺教授为共同通讯作者。
原文链接:https://www.nature.com/articles/s41467-025-59683-5
在《中国化学快报》(Chinese Chemical Letters)发表了题为Development of a comprehensive computational pipeline for cardiolipin atlas in an intermittent fasting model的线粒体中心磷脂的注释新算法,实现了对心磷脂复杂多样的结构式快速拼接。该计算框架还运用了间歇性禁食的动物组织中,绘制出多器官心磷脂图谱。更多代码信息可以访问:https://github.com/LinShuhaiLAB/CLAN.
厦门大学健康医疗大数据国家研究院为第二单位,硕士生钟晓莉和陈亮生为共同第一作者,林树海教授和集美大学曾珺教授为共同通讯作者。
原文链接:https://www.sciencedirect.com/science/article/pii/S100184172500213X
在《分析化学》(Analytical Chemistry)发表了QuanFormer: A Transformer-Based Precise Peak Detection and Quantification Tool in LC-MS-Based Metabolomics的代谢组学定量计算工具。基于transformer架构和计算机可视化方法,开发出准确识别液相色谱质谱峰并进行定量分析的端到端计算工具。不仅如此,对液相色谱中常见的保留时间漂移也有较好的校准效果。更多代码信息可以访问:https://github.com/LinShuhaiLAB/QuanFormer.
厦门大学健康医疗大数据国家研究院为第一单位,硕士生张正义和杨欢为共同第一作者,林树海教授为通讯作者。
原文链接:https://pubs.acs.org/doi/10.1021/acs.analchem.4c04531


